Bei erfolgreich angegriffenen Exchange Servern mit dem HAFNIUM Exploit, werden unter Umständen die Verzeichnisberechtigungen verändert, dies führt dazu, dass betroffene Exchange Server eine Fehlermeldung bei der Installation von Updates melden. Hier mal ein Beispiel von einem Verzeichnis, bei dem die Berechtigungen geändert wurden:
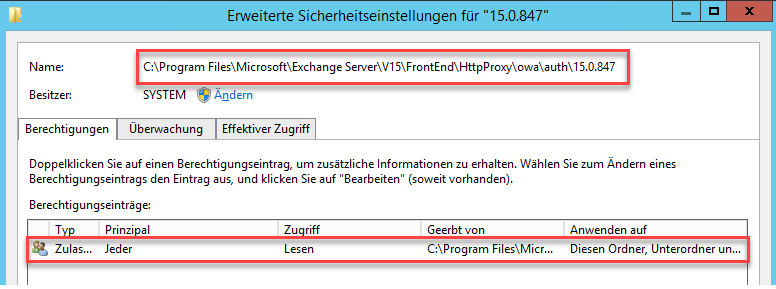
Wie im Screenshot zu sehen ist, wurden die Berechtigungen für das Prinzipal „Jeder“ auf „Lesen“ gesetzt. Diese geänderten Berechtigungen führen zu der folgenden Fehlermeldung, wenn versucht wird ein Exchange Update zu installieren:
Fehler:
Fehler beim Installieren des Produkts c:\temp\Exchange Cu23\exchangeserver.msi. Schwerwiegender Fehler bei der Installation. Fehlercode: 1603. Letzter vom MSI-Paket ausgegebener Fehler: ‚The installer has insufficient privileges to access this directory: C:\Program Files\Microsoft\Exchange Server\V15\FrontEnd\HttpProxy\owa\auth\15.0.1497. The installation cannot continue. Log on as administrator or contact your system administrator.‘.
Normalerweise hat dieses Verzeichnis andere Berechtigungen wie in folgendem Screenshot zu erkennen ist:
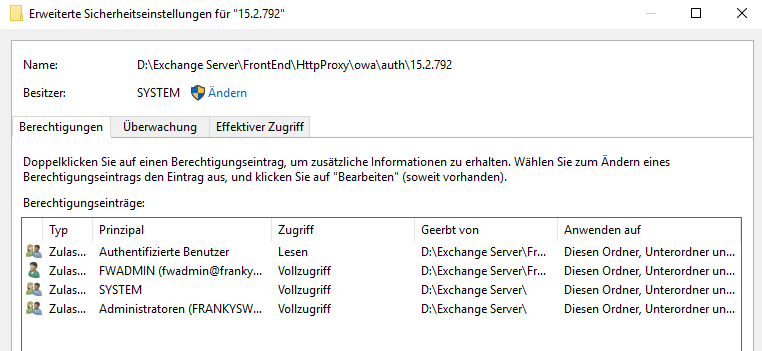
Wie einem Tweet zu entnehmen ist, beschränkt sich dies nicht nur auf den Ordner \owa\auth, sondern auch auf andere Ordner. Auf Twitter gibt es bereits einige Leute die entsprechende Tweets veröffentlicht haben:
Wer bereits geänderte Verzeichnisrechte auf Exchange Verzeichnisse gefunden hat, muss also davon ausgehen, dass der Angriff auf den Exchange Server erfolgreich war. Auch wenn sich keine Auffälligen .js oder .apsx Dateien in den Verzeichnissen finden lassen, sollte der betroffene Exchange Server sofort vom Internet getrennt werden. Ich würde in diesem Fall zur Neuinstallation raten, da dies aktuell der sicherste Weg ist, um wieder eine „vertrauenswürdige“ Installation zu haben.
Wenn möglich sollte man sich vor der Neuinstallation, noch die Logfiles und Eventlogs sichern, damit im Nachhinein noch Details zum Angriff in Erfahrung gebracht werden können.
Update 14.03.21: Das folgende kleine Quick and Dirty Script kann verwendet werden um Verzeichnisse zu suchen, auf dem das Prinzipal „Jeder“ nur Leserechte hat:
$FolderRoot = "C:\Program Files\Microsoft\Exchange Server\V15\FrontEnd\HttpProxy"
$Principal = "Jeder"
$AllFolders = (Get-ChildItem $FolderRoot -Recurse -Directory | select fullname).Fullname
foreach ($Folder in $Allfolders) {
Get-Acl $Folder | where {$_.access.IdentityReference -match $Principal -and $_.access.FileSystemRights -match "Read"}
}
Bei Servern in englischer Sprache muss das Prinzipal auf „Everyone“ angepasst werden. FolderRoot ist das Startverzeichnis, ab dem rekursiv gesucht wird.
Hi Dirk,
die Artikel von ESET und Crowdstrike habe ich auch gelesen. ESET schnitt soviel ich gelesen habe nicht so gut ab.
Mir wurde Gdata empfohlen weil in Deutschland, Bitdefender haben wir auf den Clients im Einsatz und der verrichtet da gut seinen Dienst. Wir haben auch über Carbon Black nachgedacht, aber ich fürchte das wird unbezahlbar.
Ich werde mir mal Crowdstrike anschauen. Es haben ja mehrere Akteure die Anzeichen gesehen… die ersten waren ja Volexity.
Https und DNS Tunneling ist in der Tat ein Problem. Da hilft nur Software wie Snort… Die Erreichbarkeit von WinRM zu verhindern sollte beim Einsatz einer separaten Firewall a la UTM nicht so problematisch sein. Wir haben WinRM bei allen Servern aus bis auf die Exchange.
Geoblock ist sicherlich eine gute Wahl um die Angriffe zu reduzieren… blöderweise aber arbeitet die Firma bei uns mit verschiedenen Ländern.
Ich teile die Einschätzung für die Updates, bezogen auf die Sicherheitsupdates. Da warten wir auch nicht zu lange wenn da etwas kritisches dabei ist.
DAG ist in meine Augen bei Exchange ein Muss… ohne würde ich keine Projekt angehen. Die Risiken sind viel zu hoch bei einem einzigen Server. Single Point of Failure lässt grüßen. Obendrein ist Exchange für DAG prädestiniert.
Also letzter Stand sind immer noch gut über 10.000 Exchange Server in Deutschland verwundbar. Wieviele Firmen aktuell ungebetenen Besuch noch haben, das vermag ich nicht zu beurteilen, es werden aber nicht wenige sein.
Für mich dessen Spezialisierung auf Sicherheit liegt kann ich dir nur beipflichten. Der deutsche Mittelstand will blind sein. Das ist auch der Grund warum ich fast keine Kunden mehr in Deutschland betreue, weil mir die Risiken zu groß sind. Wenn die ihre Scheunen offen lassen wollen, dann muss ich diese nicht auch noch betreuen ;)
Was mich immer fasziniert ist wieviel für ERP und co ausgegeben wird. Da wird ob zu murren Mondpreise bezahlt… aber dann bei Sicherheit geknausert wo es nur geht… Hilft halt viel wenn die tolle ERP dann befallen ist ;)
Cobald Strike Beacons wünsche ich niemanden in sein Netz. Schon gar nicht in Windows Netze. Deshalb ist dieser unbekannte Akteur der unter anderen die IP 86.105.18.116 nutze für mich das größte Problem an diesen Angriffen. Solange wir deren C&C Server nicht kennen bleibt die potentielle Gefahr riesig. Mich hat es auch gewundert, dass so wenig über diesen Akteur berichtet wurde, weil dessen Absichten sind weitaus gefährlicher als die der anderen Akteuren gewesen.
Hallo Alex,
klar untersuchen wir alle im Kontex stehenden Logs manuel sowie mit zahlreichen Tools auf definierte expressions.
Ja, der Abbruch der Abfragen war am 03.03 gegen 14:00 Uhr. Auch nach dem Patchen der Exchanger am 03.03. nachmitags kamen keine Zugriffe mehr von diesen IP’s.
Ja, es gibt leider viele Unternehmen, die inflationär Domains und Webhosting-Packages en masse ohne entsprechende Gegenprüfung des Mieters verkloppen.
Gute EDR-Endoints bieten z. B. ESET, Crowdstrike und Sophos. Das Crowstrike-Team war auch eines der ersten, dass über Heuristic/Machine Learning darauf aufmerksam wurde, was bei ihren Endkunden passierte und fingen sehr zügig mit den Untersuchungen an.
In der Tat sind Spuren mitunter schwierig zu identifizieren. Wenn z. B. https- oder DNS-Tunneling ins Spiel kommt. Da brauchst Du schon eine gute Sicht auf diese Möglichkeit. Oder mal einen Endpoint via WinRM erreichbar zu machen.
estonine.com war ziemlich schnell nach Bekanntwerden dicht, so mehrere Sicherheitsforscher.
Geoblock macht echt Sinn. Wenn ich mir angucke, was ich vor dem Geoblocking alles an IP’s, Referrern, UserAgents etc. gesehen habe, nimmt es drastisch ab. Wir haben – wo möglich – als Source nur Germany zugelassen. Wenn einer ’ne Geschäftsreise macht, kann ggf. das Land temporär geöffnet werden. Alle anderen Requests werden einfach gedropped.
Auf Serverebene habe ich in den letzten Jahren keine Windows Updates mehr erkennen können, die Windows Server zu Fall gebracht haben. Früher gab es schon mal einen BSOD nach ’nem Update. Bei VM’s kannste ja auch vorher ’nen Snapshot machen. Wir sollten an der Stelle nicht vergessen: ab dem Zeitpunkt, ab dem die Windows Updates jeden zweiten Dienstag im Monat raus sind, beginnt sofort das Reverse Engineering und die Piraten machen sich an die Arbeit. Dafür lieber mal abends einen geupdaten, fehlerhaften Server in Kauf nehmen als das Risiko eine Angriffs verlängern – meiner persönliche Meinung, mit wir seit Jahren aber sehr gut fahren. Viele Admins sind hier entweder zu faul oder (unbegründet) zu verängstigt.
DAG is eine gute Idee, entspricht aber oftmals nicht den Preisvorstellungen kleinerer Mittelständler. Denk doch einfach an die eierlegende Wollmilchsau des Small Business Server zurück…
Kosten sind das Thema. Ich kann nach 25 Jahre im IT-Biz sagen, dass der Deutsche Mittelstand definitiv blind sein will für Cybergefahren. Wenn Du aus unserer Sicht notwendige Security Items ins Feld führst, denken gleich einige CEO’s, Dir geht’s einfach um’s Geldverdienen. Vielleicht führt ja diese Angriffswelle zu einem Umdenken. Ich glaube, es sind immer noch tausender deutscher Exchanger ungeschützt.
Nein, Cobald Strike Beacons möchte ich nicht in den von uns betreuten Netzen wissen.
Hallo Alex,
ja, dieser Server (s. o.) wurde im Zeitraum 05.03. – 09.03. gleich von mehrere Gruppen kompromittiert. Da das anonymisierte Log viele Einblicke bietet und für andere lehrreich sein kann, habe ich es auf unseren Uploaded-Account hochgeladen und jeder kann es sich gerne ansehen: ul.to/al54tz9h oder uploaded.net/file/al54tz9h/compromised.txt (compromised.txt).
Ja, es gab vier Webshells, die zu unterschiedlichen Zeiten auf dem System landeten. Drei Webshells haben die bekannten JavaScripts, die vierte dient als Aufruf für PowerShell mit Parameterüberhabe. Die externe OAB-URL war auf ein Script verbogen und /owa/auth auf read-only für everybody gesetzt. Keine Hinweise auf den Angriffstypus mit dem DLL-Inject in Opera. Credential Dump in memory möglich, aber bei den forensischen Auswertungen noch keine Hinweise darauf. Vermutlich kam hier das Schweizer Taschenmesser, das Hammond erwähnt hat, zum Einsatz.
Die Logeinträge stammen ausschließlich vom Proxy-Logon-Script. Wir haben weitreichende Maßnahmen vorgenommen, um die Angriffsfläche drastisch zu reduzieren, dem Kunden aber dringend empfohlen, parallel eine neue Infrastruktur aufzubauen. Die Vielzahl der hier notwendigen Untersuchungen hätte einfach Wochen bis Monate gedauert. Für einen lateral movement konnten wir trotz intensivster Suche keinen Hinweis finden, was aber bei einer Persistenz von mehreren Tagen und auf die Schnelle der ersten Untersuchungen erst einmal nichts heißen muss.
PS: Auch wenn keine Webshell auf dem Exchanger gelandet ist, so konnten mit dem ersten Exploit sämtliche E-Mails, über die Autodiscover Auskunft gab, ausgeleitet sein. Das ist zu sehen im EWS-Log. Das wäre dann auch eine erfolgreich Kompromittierung im klassischen Sinne.
Hallo Dirk,
wenn ich mir dein Post durchlese, dann läuft es mir kalt den Rücken runter.
Danke, dass ihr die Logs hochgeladen habt. Mittlerweile sind aber denke ich alle verschiedene Vektoren auch bekannt.
Hatte der Kunde MS Defender drauf oder andere Endpoint Software?
Die vierte Webshell mit Powershell Übergabe dürfte am interessantesten sein. Da müsste geprüft werden welchen Paypload es da ausführen wollte. Wahrscheinlich ist das Ding in Basecode64 codiert. Das könnte entweder für den Miner a la estonine.com deuten oder auch für die Vorbereitung des DLL-Injekt mittels Opera.
Wenn auth auf Read Only gesetzt war, dann waren die Angreifer definitiv vor Ort. Mir ist nicht bekannt, dass die Rechteänderung aus der Ferne erfolgte bei anderen Angriffen.
Dann ist auch die Wahrscheinlichkeit groß, dass die Logs manipuliert wurden.
Hammond hatte richtigerweise darauf hingewiesen, dass es die Windows eigene Boardmitteln ja ermöglichen kritische Daten auszulesen… es braucht keine weiteren Angriffstools. Ob Procexe oder was auch immer.
Vielleicht lohnt sich die Suche nach den Mimikatz DLLs die Hammond und sein Chef am 5.3 publik gemacht haben. Die Hashes wurde da veröffentlicht.
Ich würde euch dringend raten die Logs sehr genau zu studieren. Nur daran kann man sehen wer wann raufgegangen ist. Mit etwas Glück kann man dann auch die Aktivierung der Webshells datieren.
ich gehe davon aus, dass ihr auf allen Servern nach Tasks gesucht habt.
Habt ihr das Active Directory auf Veränderungen seit dem 2.3 überprüft?… wenn die Angreifer persistence schaffen wollten, dann werden die es da gemacht haben, wenn die ran-gekommen sind. Neue User, veränderte Zugriffsrechte, alles…
Um den AD zu kompromittieren müssen die nicht mal auf dem AD gewesen sein… sie könnten ganz Einfach vom Exchange Server über die AD Adins es gemacht haben. Das ist ja die Krux an Exchange… weitreichende Rechte im AD. Wenn der kompromittiert ist, dann ist das AD in größter Gefahr.
Wenn ich ehrlich bin, dann wüsste ich nicht wie ihr die Angriffsfläche „drastisch“ reduzieren wollt. Im hiesigen Fall dürfte alles kompromittiert worden sein. Klar, Exchange updaten und dann in der Firewall Rewrite Rules. Zusätzlich OWA / ECP und co vom Internet abschotten… aber das dürfte aktuell nicht mehr viel nutzen weil die Gefahr jetzt im internen Netz sein dürfte. Der Kunde arbeitet ja dann mit den Angreifern im eigenen Netz…
Hat die Firma eine Backup Strategie gehabt? Wenn ja, dann wäre es vielleicht an der Zeit alle Server aus den Backups von vor dem Angriff wiederherzustellen und anschließend Passwörter und Kerberos zu resetten.
Die Untersuchungen können in der Tat sehr lange dauern je nachdem wie groß deren Netz ist.
Wenn es lateral movement gegeben hat, dann wahrscheinlich über smbexe und Konsorten. Hier könnten veraltete Patchversionen der Windows Server kritisch sein, besonders wenn diese nicht gegen Eternalblue und so gepatcht wurden. Obendrein gab es ja bis diesen Monat noch den üblen DNS Bug, der ja eine leichte Kompromittierung des AD Server ermöglichen konnte.
Email Abfluss ist natürlich auch möglich, wäre aber dann vor dem 2.3 passiert. Und dann in einem viel geringeren Ausmaß als man vermuten würde nach den flächendeckenden Angriffen. Das waren sehr gezielte Angriffe für den Email Abfluss… ich halte die Wahrscheinlichkeit, dass der Kunde so relevant gewesen ist, dass er ein solches Ziel war, als sehr gering.
Wir dürfen nicht aus den Augen verlieren, dass die Lücken erst ab Mitte Februar weit bekannt waren. Und den neuen Akteuren ging es nicht um die Kommunikation, sondern um die Übernahme der Server.
Die Zeilen mit dem SetObj hat dieses Webformular aus irgendwelchen Gründen nicht angenommen.
Und hier mal ein paar Zeilen Logs von einem nicht von uns betreuten Kunden, der sich am 09.03. bei uns wegen eines Verdachts gemeldet hat:
2021-03-04T17:33:04.305Z,“8582fe21-63a7-4e59-8973-3950ae60bcee“,“31.28.31.132″,“xx.xx.xx.xx“,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-05T18:18:22.709Z,“6f81bd9c-ee98-441c-a652-0d7af7c24fdb“,“113.172.167.199″,“xx.xx.xx.xx“,“/ecp/program.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-05T18:18:26.375Z,“330e5a8c-a7dd-45c9-a9ea-3c69138860ae“,“78.82.109.108″,“xx.xx.xx.xx“,“/ecp/program.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/mapi/emsmdb/?#“,“200″
2021-03-05T18:18:37.782Z,“73742c2a-d58c-4b08-9cf5-98edf8e759b8″,“180.69.56.145″,“xx.xx.xx.xx“,“/ecp/program.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/ecp/proxyLogon.ecp?#“,“241″
2021-03-05T18:19:18.917Z,“e4933121-232f-4bfa-bcbe-1c4751e1b87b“,“182.167.148.3″,“xx.xx.xx.xx“,“/ecp/program.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local/OAB/4c3f0c18-ed00-41ac-bc10-7c0a2a36b8e1/oab.xml#“,“200″
2021-03-05T18:19:23.221Z,“f4ed7c72-dc79-497d-9758-b9a733268724″,“219.254.216.56″,“xx.xx.xx.xx“,“/ecp/program.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local/OAB/4c3f0c18-ed00-41ac-bc10-7c0a2a36b8e1/25d59f7c-8d82-4ec9-adf1-61505652eba3-data-402.lzx#“,“200″
2021-03-05T21:39:53.893Z,“8cb99515-3739-4447-8f03-3fdeda8d51c1″,“161.35.76.1″,“xx.xx.xx.xx“,“/ecp/x.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~akak]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-05T21:39:54.039Z,“b626e282-83b7-44c6-b921-5342864a97d3″,“161.35.76.1″,“xx.xx.xx.xx“,“/ecp/x.js“,“X-BEResource-Cookie“,“python-requests/2.25.0″,“ServerInfo~akak]@host.domain.local:444/mapi/emsmdb/?#“,“200″
2021-03-06T09:53:33.486Z,“4dc234c8-c304-4780-9efc-c6850ece2963″,“209.58.163.131″,“localhost“,“/ecp/default.flt“,“X-BEResource-Cookie“,“Mozilla/5.0 (Windows NT 10.0 Win64 x64 rv:55.0) Gecko/20100101 Firefox/55″,“ServerInfo~localhost/owa/auth/logon.aspx?“,“500″
2021-03-06T09:53:55.430Z,“56da1f03-ba5a-4c78-901f-9fabe7eee9cd“,“34.87.189.145″,“localhost“,“/ecp/default.flt“,“X-BEResource-Cookie“,“Mozilla/5.0 (Windows NT 10.0 Win64 x64 rv:55.0) Gecko/20100101 Firefox/55″,“ServerInfo~localhost/owa/auth/logon.aspx?“,“500″
2021-03-06T15:47:11.302Z,“17c9bf2d-111b-4458-a184-7f2b1482c695″,“141.164.40.193″,“xx.xx.xx.xx“,“/ecp/x.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~akak]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-06T15:47:12.569Z,“171ceece-1386-47ba-8193-a93bbe642a61″,“141.164.40.193″,“xx.xx.xx.xx“,“/ecp/x.js“,“X-BEResource-Cookie“,“python-requests/2.25.1″,“ServerInfo~akak]@host.domain.local:444/mapi/emsmdb/?#“,“200″
Waren die Server gepatcht? Wenn diese bis zum 4.3 nicht gepatcht waren, dann muss davon ausgegangen werden, dass die kompromittiert wurden. Alles andere wäre fahrlässig.
Woher kommen diese Logs? vom TestProxyLogon? Wie schon gesagt ich würde die Logs manuell durchgehen um nach den Artefakten zu suchen.
Es gibt da wohl 2 verschiedene Gruppen… die mit program.js, die mit x.js
IPs sind es ja etliche. Deckt sich aber mit dem was ich schon früher geschrieben habe…
Die Autodiscover sind immer 200er, also bedeutet es das die angefrage Information zum gesuchten Exchange Konto bestätigt wurde. Das ist keine gute Voraussetzung.
Näher zu betrachten wären:
BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local/OAB/4c3f0c18-ed00-41ac-bc10-7c0a2a36b8e1/oab.xml#“,“200″
=> Da wäre die Frage ob im OAB external URL eine Webshell gelandet ist.
Die Zugriffe auf owa/auth haben wohl 500er zurück gegeben, dass könnte bedeuten, dass der Angriff da nicht durchgegangen ist.
Da hier aber mehrere Akteure beteiligt sind müsste nach den Artefakten der verschiedenen Akteuren gesucht werden.
Ich fürchte das euer noch nicht von euch betreuter Kunde da etwas bluten wird.
Hallo Alex,
ja, dieser Server (s. o.) wurde im Zeitraum 05.03. – 09.03. gleich von mehrere Gruppen kompromittiert. Da das anonymisierte Log viele Einblicke bietet und für andere lehrreich sein kann, habe ich es auf unseren Uploaded-Account hochgeladen und jeder kann es sich gerne ansehen: http://ul.to/al54tz9h oder http://uploaded.net/file/al54tz9h/compromised.txt (compromised.txt).
Ja, es gab vier Webshells, die zu unterschiedlichen Zeiten auf dem System landeten. Drei Webshells haben die bekannten JavaScripts, die vierte dient als Aufruf für PowerShell mit Parameterüberhabe. Die externe OAB-URL war auf ein Script verbogen und /owa/auth auf read-only für everybody gesetzt. Keine Hinweise auf den Angriffstypus mit dem DLL-Inject in Opera. Credential Dump in memory möglich, aber bei den forensischen Auswertungen noch keine Hinweise darauf. Vermutlich kam hier das Schweizer Taschenmesser, das Hammond erwähnt hat, zum Einsatz.
Die Logeinträge stammen ausschließlich vom Proxy-Logon-Script. Wir haben weitreichende Maßnahmen vorgenommen, um die Angriffsfläche drastisch zu reduzieren, dem Kunden aber dringend empfohlen, parallel eine neue Infrastruktur aufzubauen. Die Vielzahl der hier notwendigen Untersuchungen hätte einfach Wochen bis Monate gedauert. Für einen lateral movement konnten wir trotz intensivster Suche keinen Hinweis finden, was aber bei einer Persistenz von mehreren Tagen und auf die Schnelle der ersten Untersuchungen erst einmal nichts heißen muss.
PS: Auch wenn keine Webshell auf dem Exchanger gelandet ist, so konnten mit dem ersten Exploit sämtliche E-Mails, über die Autodiscover Auskunft gab, ausgeleitet sein. Das ist zu sehen im EWS-Log. Das wäre dann auch eine erfolgreich Kompromittierung im klassischen Sinne.
Folgende Informationen zum Kompromittierungsstatus eines Exchange-Servers:
Bei ALLEN unserer Kunden, die einen Exchange-Server einsetzen (12 x Exch2016, 7 x Exch2019) kam es zu KompromittierungsVERSUCHEN. Und zwar ausschließlich am 03.03.2021 zwischen 04:00 und 14:00. Alle Exchanger wurden von uns am späten Nachmittag mit dem Hotfix gepatcht.
Bei der Auswertung konnten wir folgenen Informationen gewinnen:
Die Exchanger werden erst ab einem bestimmten Level kompromittiert. Wir konnten stets folgende Reihenfolger der Kompromittierung feststellen:
2021-03-03T04:52:32.300Z,“86.105.18.116″,“87.234.59.74″,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-03T04:58:32.358Z,“86.105.18.116″,“83.236.160.6″,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-03T07:16:05.398Z,“86.105.18.116″,“87.234.59.74″,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-03T07:18:21.853Z,“86.105.18.116″,“83.236.160.6″,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-03T10:51:44.934Z,“86.105.18.116″,“87.234.59.74″,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-03T10:53:47.204Z,“86.105.18.116″,“83.236.160.6″,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-03T13:23:37.025Z,“139.59.56.239″,“87.234.59.74″,“/ecp/y.js“,“X-BEResource-Cookie“,“ExchangeServicesClient/0.0.0.0″,“ServerInfo~a]@host.domain.local:444/autodiscover/autodiscover.xml?#“,“200″
2021-03-03T13:23:40.474Z,“139.59.56.239″,“87.234.59.74″,“/ecp/y.js“,“X-BEResource-Cookie“,“python-requests/2.25.1″,“ServerInfo~a]@host.domain.local:444/mapi/emsmdb/?#“,“200″
2021-03-03T13:23:47.948Z,“139.59.56.239″,“87.234.59.74″,“/ecp/y.js“,“X-BEResource-Cookie“,“python-requests/2.25.1″,“ServerInfo~a]@host.domain.local:444/ecp/proxyLogon.ecp?#“,“241″
2021-03-03T13:24:06.893Z,,“139.59.56.239″,“87.234.59.74″,“/ecp/y.js“,“X-BEResource-Cookie“,“python-requests/2.25.1″,“ServerInfo~a]@host.domain.local:444/ecp/DDI/DDIService.svc/GetObject?msExchEcpCanary=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.&schema=OABVirtualDirectory#“,“200″
Das JavaScript-File ist nicht wirklich eine Datei. Sie MUSS für den Angriff viel mehr als im Backend erwarteter Parameter angegeben werden, existiert physikalisch aber nicht wirklich (meine Befürchtung war, dass ein JavaScript-Code evtl. den Angriff einleitet).
Einige haben spekuliert, sobald der Request mit proxyLogon.ecp ausgeführt wird, sei der Server erfolgreich kompromittiert. Das entspricht nicht unseren Beobachtungen. Auch der nachfolgende Request mit dem GetObject führt noch nicht zur Kompromittierung. Viel mehr wird hiermit die OAB-ID ausgelesen und dabei erfolgreich ein NTML-Negotiate gegenüber dem Backend ausgeführt (NT-Authority\SYSTEM). Sie BRAUCHEN die OAB-ID, um die externe URL ändern zu können. Solange es jedoch in der Befehlsabfolge keinen Request mit SetObject im Log gegeben hat, ist der Server unseren Untersuchungen nach nicht kompromittiert. Und wir haben so einiges an forensischen Tools aufgefahren, fanden aber – NICHTS.
Kein lauschendes WinRM, kein zusätzlichen AD-User, keine Webshells, keine ungewöhnlich geöffneten Ports oder Dienste, keine Änderung am TaskScheduler, keine Hinweise auf Dumps, die auf der Platte gespeichert wurden, keine gepackten Dateien, Traffic Control der Security Appliance ohne Hinweise auf größeren Traffic. Wir haben auch auf Webshells mit Status hidden und/oder system gesucht: o. B. Wir verwenden übrigens zum Suchen UltraSearch. Das sucht sehr, sehr schnell, selbt TB-große Platten durch. Es sucht übrigens nicht in jedem Ordner sondern nur den MFT durch. Der Kernel war durch Secure Boot und Kernsisolierung geschützt.
Vor der Applikation des Exchange-Hotfixes haben wir einen MemoryDump der aktuellen Maschinen für die spätere Untersuchung gemacht. Ergebnis: keine Hinweise auf Base64-codierte oder uncodierte PS-Ausführungen, kein Hinweis auf Credential Dumps im Memory.
Es sieht in der Tat so aus, als ob eine Kompromittierung erst dann möglich war, nachdem die externe OAB-URL auf ein schädliches Script umgebogen war, das das dann die Webshell herunter geladen hat. Ich glaube auch nicht, dass die Angreifer einen Teil der Logs sowie Ereignisanzeige löschen und einen Teil drin lassen.
Wer sich das Script, das für den Angriff genutzt wurde, einmal ansehen möchte: https://pastebin.com/8URdFqVq (nicht funktional). Hier sind sehr gut die einzelnen Steps der Kompromittierung erkennbar.
Hallo Dirk,
danke für die Infos.
eure Funde decken sich mit dem was andere auch beobachtet haben. Praetorian hatte am 9.3 ja den Angriff auch gut nachgebaut.
Lies dir mal deren Beitrag durch: https://www.praetorian.com/blog/reproducing-proxylogon-exploit/
Eure Server wurden aber von 2 verschiedenen Gruppen angegriffen… 86.105.18.116 und 139.59.56.239
86.105.18.116 sind auch die die uns angegriffen haben und diese Gruppe hatte ein anderes Verhalten als die anderen Gruppen. Diese Gruppe ist bisher nicht identifiziert worden. Truesec hat deren Strategie soweit offengelegt (https://blog.truesec.com/2021/03/07/exchange-zero-day-proxylogon-and-hafnium/)… das Ziel war das Einschleusen von Cobalt Strike, nicht das Abziehen von Daten. Die legten auch keine Webshell als primäres Ziel, sondern versuchten über den Opera Browser mit SideDLL ihre Schadsoftware nachzuladen.
139.59.56.239 hingegeben gehört glaube ich einen der verschiedenen chinesischen Gruppen. Man sieht an den Request an euren Servern, dass die auch anders vorgegangen sind.
Die von euch veröffentlichte Logs sind aber trunkiert oder? das POST ins ECP kommt doch erst nach dem autodiscover.xml.
Der Abruf der autodiscover.xml diente dazu die Administrator Kennung zu identifizieren.
Wie von euch richtig gedeutet ist ein „SetObject“ Request Game Over wenn er mit 200 beantwortet wird. Dann ist die Webshell über die externe URL des Objects erreichbar. Aber das ist wie gesagt nur bei den chinesischen Gruppen so gewesen.
Eine Bereinigung der Logs fand bei bestimmten angegriffenen Servern statt. Aber erst ab den 6. März oder so… Zu dem Zeitpunkt waren die Angreifer über die Webshell zurück gekommen und haben dann angefangen ihre Spuren zu verwischen. Bei einigen Servern haben die dann auch die Lese / Schreibrechte auf unterschiedliche Verzeichnisse von Exchange geändert, damit keine andere Gruppe mit dem Exploit Erfolg haben konnte. Danach wurde von denen Webshells versteckt und Tasks angelegt zur Verbreitung ins Netzwerk und um Persistenz auf dem Server zu haben. Die Änderung der Lese / Schreibrechte ist dann beim Einspielen der Sicherheitsupdate durch die Firmen aufgefallen, weil diese immer abbrachen wegen der verstellen Rechten. Einige haben sich dabei nichts gedacht, andere waren aber vorsichtiger und haben nach langem Suchen auf den Servern Webshells entdeckt.
Hi Alex, danke für die Ergänzungen.
Ne, die chronologische Abfolge der Logs ist schon authentisch. Das sind die Ergebnisse in der Reihenfolge, wie sie das Test-ProxyLogon.ps1 am 03.03 gefunden und ins CSV geschrieben hat.
Was ich bemerkenswert fand: ab 14:00 Uhr hörten alle Requests bei allen unseren Kunden schlagartig auf! Der letzte Request ist, glaube ich, vom 13:59 Uhr. Sie hätte nur zwei, drei weitere Requests gebraucht und der Server wär‘ kompromittiert gewesen!
Bei vielen Servern blieb es beim Autodiscover-Request, aber über den GetObjekt-Request ging kein einziger hinaus. Hatte DigitalOcean hier den Virtual Servers, von denen die erste Angriffswelle ausging, den Strom gezogen? Traffic-mäßig muss das ja aufgefallen sein. Egal, ich ärgere mich nicht darüber, dass sie es nicht getan haben.
Wir haben bei den Kunden Endpoints mit EDR zu sitzen. Wenn da etwas aus eine lauenden Prozess wie CMD oder PowerShell aufgerufen worden wäre, hätte der Endpoint angeschlagen (Test). Der reagiert manchmal sogar schon bei direkten SystemCalls.
Auch bei einer Suche nach einem lateral movement konnten wir rein gar nichts finden. Post-exploitation persistence hinterläßt aber IMMER Spuren. Du musst sie nur sehen können. Aber da war rein gar nichts. Auch nicht im Memory. Sicherheitshalber haben wir jedoch zusätzlich bei allen DC’s einen zweimaligen Reset des Kerberos-Kontos gemacht. Vorsicht ist die Mutter der Porzellankiste.
Mich würde hier von den anderen mal deren Zugriffsversuche samt IP’s interessieren.
Was ich jedem nur raten kann:
1. UEFI Safe Boot an
2. Kernisolierung auf VM’s an (ab Server 2016, sowohl bei Hyper-V als auch VMware vSphere)
3. Credentials Guard an (außer auf DC’s, damit nicht kompatibel)
4. Wenn machbar: Zugriffe für tcp/443 nur von den Countries, aus denen Zugriff kommen darf (reduziert Anzahl BruteForce ungemein!)
5. Windows Updates spätestens 1-2 Tage nach release installieren
6. Cumulative Updates nach 2-3 Wochen (vorher auf Fehler recherchieren!) zeitnah installieren. Es ist ein Irrglaube, dass CU’s bei sauber konfigurierten Exchange-Installs Probleme machen. Sie dauern halt nur (1 – 2.5 h, je nach Hardware und Installation)
7. Security Appliance, die ständig mit dem Endpoint kommuniziert und bei Bedarf Maßnahmen ergreift
8. Erlaubnis vom Auftraggeber geben lassen, bei Eintritt in den Incident Response Mode sofort alle Stecker zu jeder Tages-/Nachtzeit ziehen zu dürfen (Haftungsausschluss definieren!)
Hallo Dirk,
die chronologische Abfolge ist authentisch? Hast du mal selber in den Logs geschaut und nur den Inhalt der Datei durch Proxylogon genommen? Ich empfehle die Logs selber durch-zugehen… bei uns waren 80% der Zugriffe nicht vom Skript vermerkt worden.
Am besten die Logs nach Schlagwörtern wie „python“ und x.js und so weiter durchsuchen. Da gibt es ja einige die in den diversen Sicherheitsbeiträgen genannt werden.
War der Abbruch der Anfragen am 3.3? Weil ich habe die IP 86.105.18.116 noch am 4.3 morgens aktiv gesehen bei uns in den Logs. Aber da waren unsere Server gepatcht und die haben bei dem ECP POST einen 500er zurück bekommen.
Ich hatte die IP 86.105.18.116 am 3.3 bei AbuseIP und bei Digital Ocean gemeldet. Und wie ich bei AbuseIP gesehen habe war ich unter den ersten die die IP gemeldet haben (der dritte glaube ich). 3 Tage später waren da einige mehr Einträge. Am 4.3 hatte das Huntress auch gemacht.
Truesec schrieb in seinem Post am 7.3, dass die Domains inkl. IP nicht mehr erreichbar waren.
Es ist davon auszugehen, dass Digital Ocean reagiert hat, aber wann ist die Frage.
Wenn ich ehrlich bin, so haben diese Unternehmen nicht ein Auge darauf… das ist auch der Grund warum Angreifer meist bei solchen Vserver Anbieter mieten. Da fällt es erstmal nicht auf, bis sich die Beschwerden sammeln und das kann etwas dauern.
Wie von Truesec beschrieben ging der Exploit wohl bei einigen durch. Zeitpunkte nannte Truesec aber nicht.
Die Anfragen mit autodiscover und mit POST im ECP waren wohl Prüfungen auf vorhandensein der Schwachstelle würde ich vermuten. Wir hatten diese am 3.3 um 04H25 und um 10H35.
Ich kann aber keine Informationen zum Verhalten nach dem 4.3 geben, weil da waren unsere Server gepatcht und deshalb war deren Angriffsvektor zu dem Zeitpunkt bei uns Makulatur. Obendrein haben wir am 5.3 und 6.3 dann noch mehrere Webservices abgeschirmt und das Filtern der Cookies aktiviert. Ab da sollte jeder Angreifer draußen gewesen sein, egal mit welchen Vektor er es probieren wollte, noch bevor er mit dem Server kommunizieren konnte.
Endpoints mit EDR ist eine gute Sache. Was haben den eure Kunden für ein Produkt da? Wir überlegen gerade das bei uns nachzurüsten. Gdata oder Bitdefender Gravity Zone Ultra.
Allerdings muss auch gesagt werden, dass selbst Endpoints nicht sofort reagiert haben. Huntress hatte in seinen ersten Reports am 3.3 und 4.3 aufgewiesen, dass fast alle Endpoints die Angriffe nicht gesehen haben. Meist weil die Verzeichnisse laut Microsoft Vorgaben von der Überwachung ausgenommen waren, oder weil die Angriffsvektoren den Endpoints unbekannt waren. Das hat sich dann ab dem 5.3 geändert, wo die Endpoints mittels Updates angefangen haben die Gefahr zu erkennen und dann auch Webshells und co teilweise aufgehalten haben.
Post-Exploitation persistence hinterlässt immer Spuren, solange diese nicht gelöscht werden. Wichtig ist die Spuren zu kennen, weil die Angreifer wie wir gesehen haben ihre persistence gut tarnen (Tasks mit sehr ähnlichen Namen zu Windows Diensten, Sideloading von Schadsoftware über DLLs von legitimen Programmen wie Opera…)
Für die Memory persistence reicht ja ein Reboot um das Problem zu beseitigen, aber dann sind die Spuren auch weg. Deshalb vorher immer ein Abbild der Memory machen.
Das Reset von Kerberos Tickets wahr sicherlich nicht falsch. Haben wir auch gemacht. Zusätzlich alle Passwörter aller Konten geändert. Sicher ist sicher.
Was die IPs angeht, so kannst du in den diversen Sicherheitsartikeln im Web nachschauen… es sind gut über 100 verschiedene gewesen und es kamen immer wieder neue dazu. Da den Überblick zu behalten… Wir haben nach 50 IPs am 6.3 aufgehört IPs manuell zu blacklisten. Vor allem auch weil alle diese Server gemietet waren und deshalb nachdem diese abgeschaltet sein werden, wahrscheinlich die Angriffssoftware nicht mehr drauf haben werden.
Sinnvoller kann es sein die Domains zu sperren die in den Reports auftauchen wie p.estonine.com und andere. Aber diese Domains sind Sicherheitsfirmen wie Sophos und co auch bekannt und Traffic zu diesen Domains wird automatisch geblockt und gemeldet.
Zu deinen Punkten.
1 bis 3: Geht nur für die die Windows Server 2016 oder neuer einsetzen.
4: Ja, kann man machen. Sophos UTM aber unterstützt es soviel ich gesehen habe nicht separat für seine WAF. Wenn dann muss der gesamte Traffic mittels Geoblock gefiltert werden.
Alternative ist Dienste wie ECP, OWA und co einfach über die WAF von außen zu sperren. Und dann mittels ACL einzelne IPs dafür freizuschalten falls nötiger Zugriff von außerhalb.
5: Ja, ist 2-seitiges Schwert… es gab ja schon Updates die mehr kaputt gemacht haben als repariert haben. Ich unterscheide zwischen Sicherheitsupdate und andere. Sicherheitsupdates sollten unverzüglich eingespielt werden.
6: Dem kann ich nur zustimmen, immer versuchen auf der aktuellen CU zu sein. 2-3 Wochen reichen meist aus um Probleme zu erkennen. Am besten ist es einen DAG zu fahren, weil dann kann man auch einen Server als Testkaninchen missbrauchen und notfalls über Backup zurück holen. Für die die sich keine Testumgebung leisten wollen ;) => Es hat sich auch gezeigt, dass nur wer auf aktueller CU ist schnell reagieren kann… die Patches am 2.3 waren nur für die 2 neuesten CUs der jeweiligen Exchange Version.
7: Ja, nach dem was passiert ist sieht es so aus als ob es von der Stufe einer Empfehlung, nice to have auf notwendig geändert werden sollte. Auch wenn es nicht im gleichen Moment alles verhindert, so kann es doch helfen. Es gab ja etliche betroffene die davon erzählt haben, dass dank dieser im Nachhinein schlimmeres verhindert wurde. Die Kosten sind aber nicht zu vernachlässigen und das wird den wenigsten Geschäftsführen schmecken. Es ist das allgemeine Probleme, dass Firmen nie in Sicherheit investieren wollen und wenn irgendwo gespart werden soll, dann ist es immer die Sicherheit, weil die sieht man eben nicht. Bis der Notfall kommt und diese dann zeigen kann was diese kann oder eben nicht, weil die nicht mehr da ist ;)
8: Aus Erfahrung sehr sehr schwierig. Hätte ich es bei uns gemacht, so wäre der Teufel los gewesen. Besser ist es für den Fall vorbereitet zu sein. Wir haben einen DAG und nur einen Server wo die Webservices erreichbar sind. Somit konnten wir am 3.3 alle Server patchen, den getroffenen Server isolieren und anstelle einen anderen der DAG Server für die Webservices nach außen freischalten der gepatcht war. Dank DAG ohne Unterbrechung des Verkehrs.
Wenn man im Incident Response Mode geht, so ist es wichtig die Maßnahmen aufzuwiegen. Alle Stecker ziehen zu dürfen werden die wenigsten Firmen akzeptieren. Besser ist es die Infrastruktur vor Ort so aufzubauen, das man geteilte Netze hat und somit bei Problemen erstmal Teilnetze stilllegen kann. Es sollte immer die Möglichkeit geben jede Maschine getrennt vom Netz isolieren zu können.
Aus Erfahrung ist ein Eingreifen bei gut durchdachten Netzen mit entsprechenden Sicherheitsvorkehrungen kaum nötig. Wer beispielsweise einen Reverse Proxy mit Authentifizierung vor den Exchange hatte, der ist vor solchen Angriffen wie die vom 3.3 gut geschützt. Wer einen DAG mit mehreren Servern hatte, der konnte auch den Ausfall für den Kunden geschmeidig organisieren. Wer Endpoint mit Advance Defense Protection hatte, der wurde auch teilweise vor schlimmeren bewahrt. Was im hiesigen Szenario keinen Einfluss hatte war das Einsetzen einer WAF ohne vorherigen Authentifizierung, weil der Angriff eben durch diese hindurchging.
Sprich es kommt immer wieder darauf an wie-viel der Kunde in Sicherheitsvorkehrungen investiert. Hat er viel investiert, so wird er solche Angriffe meist relativ problemlos überstehen. Hat er zu wenig oder falsch investiert, so können solche Angriffe einen sehr hohen Schaden verursachen aus dem der Kunde dann wie ein kleines Kind das sich an einer heißen Kochplatte verbrannt hat, lernt. Und manchmal ist der Schaden so groß, dass es die Firma niederreißen kann.
In meinen Augen haben alle Firmen die nicht bis zum 4.3 die Lücken geschlossen hatten ein nachhaltiges Problem. Jede dieser Firmen muss davon ausgehen, dass sie kompromittiert worden ist. Und die Kompromittierung zu überprüfen und zu bereinigen dauert lange und ist aufwendig. Vor allem weil eben Spezialisten ins Boot geholt werden müssen. Wer glaubt, dass die Tools von Microsoft ausreichen, der irrt gewaltig… diese Tools suggerieren sogar eine falsche Sicherheit, weil sie viele der Angriffe gar nicht erst erkennen. Nur das eigene Filtern der Logs kann Gewissheit bringen. und anhand der Funde dann nach den passenden weiteren Spuren suchen.
Wer beispielsweise Cobald Strike oder ähnliche Software in einem Netz jagen muss, der weiß wovon ich spreche. Da ist ein sehr sehr langer Atem nötig um da als Gewinner vom Feld zu ziehen.
Oft muss darüber nachgedacht werden sogar das gesamte Netz neu aufzubauen und das kann dann den Firmen das Genick brechen.
Habe ebenfalls einen Exchange der betroffen ist. Trotz installation des Updates am 3.3. am Abend war der Angreifer zwei Stunden vorher schon am System. :-(
Dieser hatte sich winrm über https freigeschaltet. Eine Webshell war ebenfalls aktiv. Werde die Maschine neu installieren, da es sich um eine relativ kleine Installation handelt….
Bin auch betroffen, bei mir war eine ASPX-Datei erstellt werden und einige Log-Einträge, die ich noch nicht deuten kann.
Aber:
C:\Program Files\Microsoft\Exchange Server\V15\FrontEnd\HttpProxy\owa\auth\Current\themes\resources\logon.aspx
C:\Program Files\Microsoft\Exchange Server\V15\FrontEnd\HttpProxy\owa\auth\Current\themes\resources\lgnrop.aspx
Kann mir einer sagen, gehören die da rein??
Ich habe diese jetzt mal vorsorglich gelöscht, die wurden erst gestern/vorgestern erstellt und kommen mir dubios vor, alle anderen Files in dem Ordner sind von 2019 oder sowas….
Warum hast du dir nicht einfach deren Inhalt angesehen?
Dann hättest du sehen können ob es Webshells waren oder was auch immer.
Hast du mal das Microsoft Script zum vergleichen der Exchange Hashes benutzt? Da sollten fremde Dateien auffalen.
Mehr Infos findest du bei Trimarc unter https://www.trimarcsecurity.com/single-post/2019/02/12/Mitigating-Exchange-Permission-Paths-to-Domain-Admins-in-Active-Directory
Ansonsten ganzen unten bei Praetorian steht auch das modifiziertes Powershell Skript um die Rechte der Exchange Systeme zu prüfen. Siehe https://www.praetorian.com/blog/reproducing-proxylogon-exploit/
Der Beitrag ist mir in der Flut der Infos zu dem Thema irgendwie durch die Lappen gegangen und ich hab gestern dem BSI dazu diese Infos geschickt für die Variante, die die Berechtigungen umschreibt:
Es gibt eine „Variante“ des Angriffs, bei der die ECP Server Logs und andere Logs, die Test-ProxyLogons.ps1 prüft, bereinigt werden. Webshells ursprünglicher Angreifer werden, sofern noch vorhanden, entfernt. Test-ProxyLogons.ps1 gibt zu diesem Angriff keinerlei Informationen aus und weist dadurch nur auf frühere Angriffe hin. Die Webshell wird versteckt und als Systemdatei markiert. Die Berechtigungen auf dem ECP und OWA Verzeichnis werden auf ausschließlich Jeder nur lesen/ausführen gesetzt, um andere daran zu hindern, den Server erfolgreich anzugreifen. Auf Grund der defekten Berechtigungen schlägt das Update fehl. Normalerweise werden OWA und ECP beim Update komplett gelöscht und neu erstellt, scheinbar passiert dies ebenfalls nicht, so dass die Webshell auch das Update überlebt.
Wer sich also ausschließlich auf Test-ProxyLogons.ps1 verlässt, dann keine Webshells anderer Angreifer findet, und sich denkt „Die Berechtigungen waren kaputt, da haben wir ja nochmal „Glück“ gehabt“, der hat unter Umständen ein Problem.
Es scheint dieselbe Variante zu sein, von der John Hammond im Huntress Blog, spricht. Was er bei seiner „stage five“ Analyse auslässt oder übersieht, ist, dass die stage five effektiv ein kompletter Wurm ist. Die Hashes aus dem lsass Memorydump werden in dem Skript direkt verwendet. Das 6MB Powershell-Skript besteht aus vielen unterschiedlichen Tools, z.B. eine Modifikation von https://github.com/Kevin-Robertson/Invoke-TheHash/blob/master/Invoke-SMBExec.ps1, wodurch es unter anderem SMBExec mit pass-the-hash mit und ohne SMB Signing unterstützt.
Danke für das Teilen.
Sehr interessant der Fund… ich hatte das in Huntress Berichterstattung übersehen.
Dieses Vorgehen dürfte aber von nach dem 4. März sein vermute ich. Wer da schon gepatcht hatte, der sollte wohl davon nicht betroffenen sein, vorausgesetzt es waren keine Webshells vorhanden.
Das ProxyLogon nicht alles findet sollte ja bekannt sein… bei uns waren die Einträge in den ECP Logs nicht aufgefallen.
Das die Angreifer die Dateien als „Systemdateien“ ausgeben damit diese versteckt sind ist ja auch seit den 6. März bekannt. Einige Sicherheitsforscher haben darauf hingewiesen.
Deshalb sollte ja der betroffene Server wenn möglich aus einem Backup wiederhergestellt werden. Nur so kann man einigermaßen sicher sein, dass das was aufm Server gelandet ist auch weg ist. Oder neu installieren wie Frank es hier erklärt hat.
Konntest du prüfen ob das MSERT diese versteckte Systemdateien sieht und prüft? Ich habe es ehrlich gesagt nicht getestet. Ich hatte manuell in den Verzeichnissen danach gesucht, nachdem ich die Option zur Anzeige der Systemdateien aktiviert hatte.
Ich habe das auf einem Server gefunden, der am 05.03. das erste Mal angegriffen wurde. Test-ProxyLogons.ps1 hatte genau hier das Problem verursacht, dass man dachte alles sei in Ordnung weil die Berechtigungen kaputt waren, weshalb sich das Update nicht installieren lies, und ansonsten auch nichts zu finden war. Nach dem Update wurde der Virenscanner vorsichtshalber auf dem System mehrfach täglich mit einer Tiefenprüfung beauftragt, um nicht doch irgendwas zu übersehen, was mit einem späteren Signatur Update evtl. erkannt werden könnte, aber schon länger irgendwo versteckt gewesen ist. Dadurch wurde dann halt die versteckte Datei entfernt und gemeldet. MSERT habe ich leider nicht darauf angesetzt.
Danke für das Update.
Weiss du wo diese Datei abgelegt war und wie die hiess?
Es deckt sich aber mit meinen Infos. Ab den 4.3 sind weitere Akteure ins Spiel gekommen, die andere Strategien gefahren haben als die, welche bis zum 3.3 angegriffen haben.
Die die am 5.3 angegriffen wurden haben auch fast alle die Tasks abgekommen und andere übleren Sachen. Davor beschränkte es sich ja eher auch Webshells und ein LSASS Dump und so.
Das Proxylogon kein wirklichen Wert hat konnte ich selbst auch in Erfahrung bringen. Ich habe die aktuellste Version auf unseren kontaminierten Server laufen lassen und im Gegensatz zu dem ganzen frühen TestHafnium hat es nichts gefunden. Ich bin da fast vom Stuhl gefallen.
In meinen Augen versagt hier Microsoft komplett.
Ohne die Infos von Huntress und co. wären wir so ausgeliefert gewesen…
Habe da was im Log (NGEN) von Net Framework gefunden!
Hier ein kleiner Ausschnitt:
03/03/2021 23:06:16.303 [8288]: Command line: C:\Windows\Microsoft.NET\Framework\v4.0.30319\Ngen.exe Update /Queue /Delay
03/03/2021 23:06:16.869 [8288]: ngen returning 0x00000000
03/03/2021 23:14:41.156 [15688]: NGen Task starting, command line: „C:\Windows\Microsoft.NET\Framework\v4.0.30319\NGenTask.exe“ /RuntimeWide /StopEvent:5760
03/03/2021 23:14:41.292 [15688]: Attempting to acquire task lock.
03/03/2021 23:14:41.297 [15688]: Acquired task lock.
03/03/2021 23:14:41.313 [9324]: Command line: C:\Windows\Microsoft.NET\Framework\v4.0.30319\ngen.exe RemoveTaskDelayStartTrigger /LegacyServiceBehavior
03/03/2021 23:14:41.338 [9324]: ngen returning 0x00000000
03/03/2021 23:14:41.345 [15688]: Executing high priority queued items
03/03/2021 23:14:41.354 [18952]: Command line: C:\Windows\Microsoft.NET\Framework\v4.0.30319\ngen.exe ExecuteQueuedItems /LegacyServiceBehavior
03/03/2021 23:14:41.360 [18952]: Executing command from offline queue: uninstall „Microsoft.Security.ApplicationId.PolicyManagement.PolicyModel, Version=10.0.0.0, Culture=Neutral, PublicKeyToken=31bf3856ad364e35, processorArchitecture=msil“ /NoDependencies
03/03/2021 23:14:41.399 [18952]: Uninstalling assembly Microsoft.Security.ApplicationId.PolicyManagement.PolicyModel, Version=10.0.0.0, Culture=Neutral, PublicKeyToken=31bf3856ad364e35, processorArchitecture=msil
03/03/2021 23:14:41.400 [18952]: Executing command from offline queue: install „Microsoft.Security.ApplicationId.PolicyManagement.PolicyModel, Version=10.0.0.0, Culture=Neutral, PublicKeyToken=31bf3856ad364e35, processorArchitecture=msil“ /NoDependencies /queue:1
03/03/2021 23:14:41.401 [18952]: Executing command from offline queue: uninstall „Microsoft.PowerShell.Commands.Utility, Version=3.0.0.0, Culture=Neutral, PublicKeyToken=31bf3856ad364e35, processorArchitecture=msil“ /NoDependencies
Vielen Dank für die Info! Das Problem bestand bei uns auch, ich war etwas in Eile, da ich erst !!am 8.3.!!! davon erfuhr. Die Informationsverteilung war hier mehr als schlecht. Ich meine Google hat mich auf dem Handy darauf aufmerksam gemacht (war mehr Zufall, da ich von den Corona News mittlerweile stark gelangweilt bin). Ich habe sofort während des Betriebs alles lahm gelegt und das aktuelle CU8 für den EX2019 installiert (war noch CU5) und musste dabei feststellen das es 4-5x deswegen abbrach. Habe die Berechtigungen schnell angepasst und dachte wieder das es wie üblich ein hausgemachter Fehler von MS sei. Nach dem CU Update und dem Patch fanden die bekannten Tools dann auch jede Menge in den Logs und 3-4 .aspx Dateien. Ich habe alle MA gesperrt und zur Kennwortrücksetzung aufgefordert, alle Dienst und Adminkennwörter geändert, Country Blocking in der Sophos aktiviert, sowie Webserver Security aktiviert. Umkehrauthentifizierung geht ja leider wegen dem hybriden Quatsch nicht sofern ich weiß (was übrigens auch generell der Grund für die Offenheit war). Andere Server waren nicht befallen, auf allen läuft jetzt auch Kaspersky Endpoint Security, was langfristig in die Hose gehen wird, aber aktuell läuft es. Seit dem keine Logeinträge mehr und keine Unauffälligkeiten. Einzig öfters gesperrte AD Nutzer die über Azure aus angreifen und nach 3x falscher Kennworteingabe ausgesperrt werden, auch im AD.
Ich erwarte dazu eigentlich eine ins Auge stechende Mail oder Information seitens MS, für jedes O365 Wehwehchen bekomme ich ja auch Infos! Wir wurden zwar eh am 2.3. um 4Uhr morgens schon befallen, aber dennoch sind 6 Tage eine lange Zeit! Zumal dazu ja nichts aus dem WSUS kommt und ich jetzt wirklich nicht täglich nach Updates auf einer so unübersichtlichen und mit selbstbeweihräucherung überladenen Seite von MS suchen kann. Über schnelle Quellen für alle zukünftigen Vorkommnisse mit Windows und Exchange etc. wäre ich aber sehr dankbar. :(
Kleiner Tipp: Abonniere dir den RSS-Feed von Franky oder Heise Securtiy, dann hättest du gleich bescheid gewusst ;-) Aber ich glaube in deinem Fall wäre selbst das zu spät gewesen. Richtig public wurde das ja erst am 3.3.
Danke für den Tipp, ist abonniert! :)
Nach deinem Bericht würde ich mich nicht mit den von dir bereits durchgeführten Sicherheitsmaßnahmen zufrieden geben. Die Jungs hatten demnach vom 02.03 bis zum 08.03. massig Zeit auch noch tiefer in das Netzwerk einzudringen als nur auf Exchange Ebene. Das Active-Directory sehe ich da ganz stark in Gefahr.
Ich habe alle Server gescannt, mit dem MSERT und mit dem Kasper, der bis jetzt eigentlich immer alles gefunden hat. Es ist nichts zu finden! Aber das hat ja ertsmal nichts zu heißen…
Prüfe mal alle Berechtigungen im Active Directory. Neue Nutzer, geänderte Rechte und so weiter.
Wenn die Angreifer mehrere Tage Zeit hatten, dann wird das deren Ziel gewesen sein. Das war es zumindest für die die sich in den Netzwerken verbreiteten… es ist immer der AD…
Hast du auf allen Servern die Tasks überprüft? Einige Angreifer haben Tasks angelegt um persistence zu erreichen. Die Namen der Tasks stehen in den Kommentaren zum Artikel von Frank zu den Sicherheitspatches .
Das was du im .Net Log gesehen hast deutet auf so etwas auch hin.
Hatte ebenfalls einen Kunden wo auch die Rechte im ECP\Auth auf Jeder gestellt waren. Hier wurde leider von unserem Vorgänger der externe Zugriff auf das ECP NICHT mittels Access Rule unterbunden, ich vermute das es damit im Zusammenhang steht ob nur das OWA Verzeichnis betroffen ist.
Das ECP zu sperren hätte den Angriff auch nicht gestoppt. Es gibt 3 RCEs und nur einer war für das ECP… soviel ich bis jetzt gesehen habe wurden alle 3 RCEs probiert.
Jedes der 3 RCEs ermöglicht das Ablegen von Daten an jedem Ort nach erfolgreichen Ausführen.
Das einzige was geholfen hätte, wäre das die Webdienste wie OWA, ECP, OAB, ActiveSync, RPC und co nicht vom Internet erreichbar gewesen wären.
Wir alle wussten, dass es ein Risiko ist die Webdienste nach außen zu haben… aber keiner hat mit dem gerechnet was jetzt passiert ist, ein Request forgery der 3 RCEs im Anschluss ermöglicht, bevor überhaupt Gegenmaßnahmen bekannt sind.
Es ist mittlerweile offensichtlich, das Microsoft fahrlässig gehandelt hat. Die haben sich viel zuviel Zeit mit dem Patch gelassen und es erst so den Angreifern ermöglicht sich so gut vorbereiten zu können.
Hallo georgg,
der Screenshot war von mir – hatte ich Frank heute geschickt.
Habe 3 Server bei Kunden die es erwischt hat. 2013/16 – 19 war okay, weil Cu 8.
Habe die Berechtigung wieder hergestellt und dann die letzten CU’s installiert. Danach noch alles was Microsoft auf bithub anbietet gemacht.
Ein gutes Gefühl habe ich habe nicht – wer weiß wie weit die im Netz gekommen sind.
Schöne Bescherung mit Evtl. Spätfolgen die man nicht kennt!
Bislang habe ich das nur beim OWA/AUTH-Verzeichnis und drunter gesehen. Ist ja logisch, dass ein Angreifer damit die Installation des Updates erst mal erschweren will. Ansonsten wird das Exchange Update.MSI auch ein Log raus, welche Dateien es nicht schreiben kann.
Ich kenne leider kein Skript, welches eine gegebene Installation mit einer „Standardinstallation“ vergleicht.
Microsoft bietet unter https://github.com/microsoft/CSS-Exchange/tree/main/Security neben dem Test-Proxylogon-Skript das PowerShell-Skript CompareExchangeHashes.ps1an. Allerdings vergleicht es keine Berechtigungen sondern nur die Hashes der jeweiligen Standardinstallation mit den Hashes der vorhandenen Dateien.
Danke Frank für die Info, Frank! Wo kann man nachsehen welche anderen Verzeichnisse betroffen sein könnten? Microsoft hat die Hafnium Seite im Security blog seit 8. März nicht mehr upgedated.
Hallo georgg,
ein weiterer Leser berichtet über das /ecp/auth Verzeichnis, ich konnte es allerdings nicht verifizieren. Ich habe den Artikel um ein kleines Quick & Dirty Script erweitert um nach verdächtigen Berechtigungen zu suchen.
Gruß,
Frank
Hallo Frank,
im /etc/auth Verzeichnis kann ich das bestätigen.
Gruß
Alex